适配知网“连续13字符相似+语义识别”算法,重点规避连续重复、引用不规范、AI生成特征,实现精准降重。
知网核心特性:
① 数据库覆盖核心期刊、硕博论文、专利、外文文献,比对范围最广;
② 算法升级后,不仅识别连续字符重复,还能通过“语义聚类”识别改写后的相似段落;
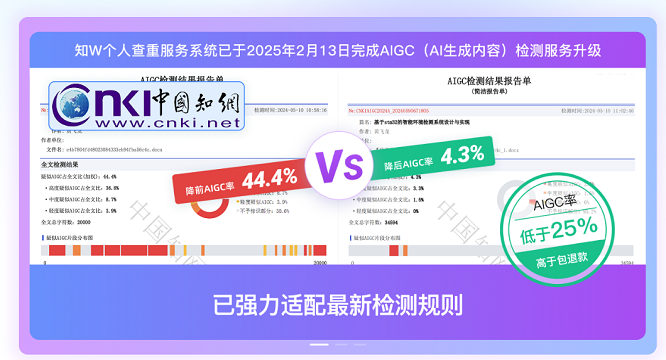
③ 新增AIGC检测模块,可识别AI生成内容。
针对性降重策略:
1. 规避连续13字符重复:拆分长句,插入原创语句或细节。示例:原标红句“区块链技术的核心是去中心化、透明化、不可篡改,这些特征使其在金融领域广泛应用”→ 拆分后“去中心化、透明化与不可篡改是区块链技术的核心优势。结合金融领域对信任构建、风险控制的核心需求,该技术有望在支付结算、跨境金融等场景深度落地”;
2. 强化语义原创:避免简单同义词替换,重构句子逻辑。示例:原句“大数据技术能提升智能制造效率”→ 改为“大数据技术通过分析设备运行数据,提前预警故障并优化生产参数,从而提升智能制造企业的生产效率与产品合格率”;
3. 规范引用格式:严格按知网要求标注参考文献(优先标DOI),引用内容≤段落10%,引用后加原创分析;
4. 规避AI生成特征:减少标准化句式、通用衔接词,加入个性化观点与具体案例。
高频避坑点:① 不可抄袭硕博论文、核心期刊文献(知网比对库覆盖最全);② 避免大段引用(超过2行),优先碎片化引用;③ 降重后用知网预检,重点优化标红的语义相似段落。
